Autonomous multi-agent DAG pipeline
A 7-node Directed Acyclic Graph generating localized product content for 11 enterprise clients across 5 countries. Human-supervised autonomous execution. Deterministic validation fires first; the LLM activates only if the gate passes.
Problem
Enterprise clients required localized, SEO-compliant product pages across dozens of cities. Manual creation is mathematically impossible at ~10.5M product-location combinations per month.
Approach
A fail-closed 7-node DAG with RAG-constrained generation (Google SPAM policies + E-E-A-T standards). Full architecture, deep-dives, and live trace are documented on the Pipeline page.
Result
400K+ impressions across 3 client properties, 68.9% average pass rate per boundary, $0.0006/PDP end-to-end. 234 managed websites across 5 countries.
Why this exists
Multi-location retailers need unique, localized product pages for every item in every city they serve. At enterprise scale, this means millions to billions of pages — each requiring localized copy, structured data, and policy-compliant content. Manual creation doesn’t get close.
Validated with SEO leadership at retailers operating 10–10,000+ store locations. The content gap is six orders of magnitude beyond manual capacity.
No CMS integration. No developer hours. No API setup from the client. Operates as an external, headless discovery layer that activates with a single switch.
Every generated page carries audited structured data (Schema.org, JSON-LD) and policy-checked copy against retailer compliance rules — the prerequisite for being indexable inventory, not noise.
Verified evidence — Google Search Console
Aggregate results across 3 active client properties — verified via Google Search Console.
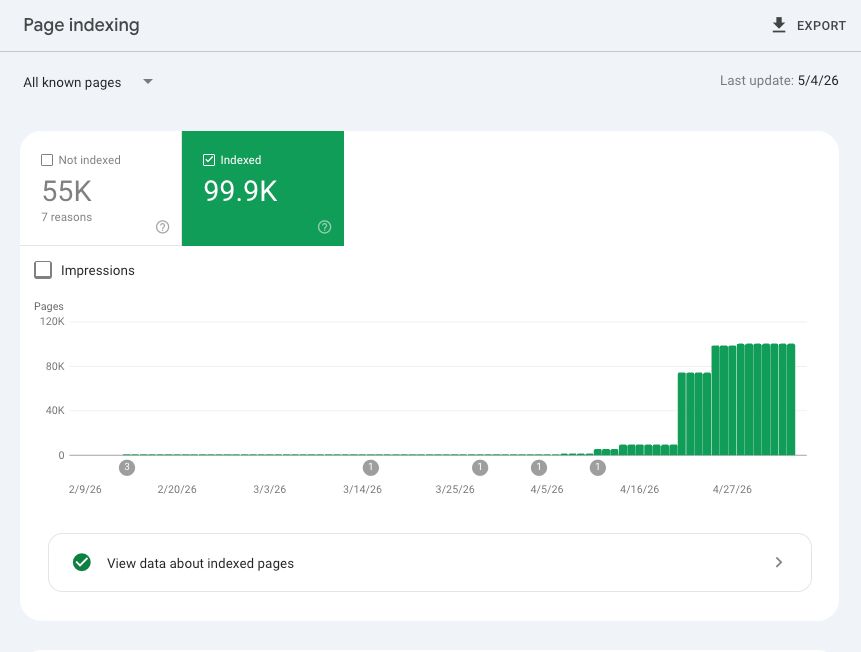
Hockey-stick from 0 → 99.9K in ~60 days. Autonomous pipeline output.
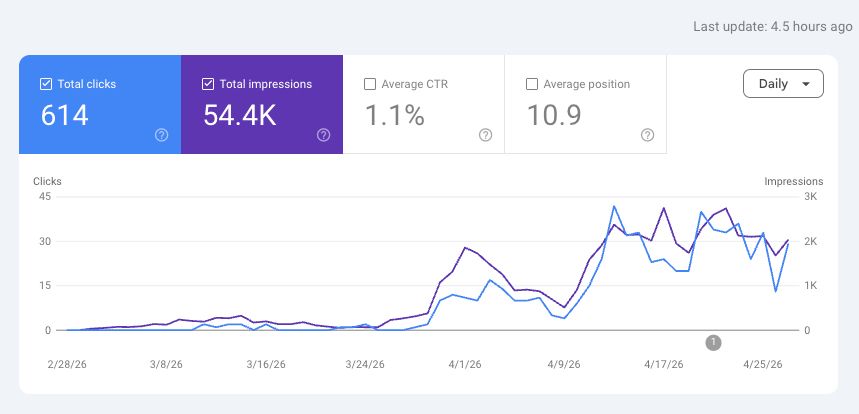
1.1% CTR, avg position 10.9. Zero manual content creation.
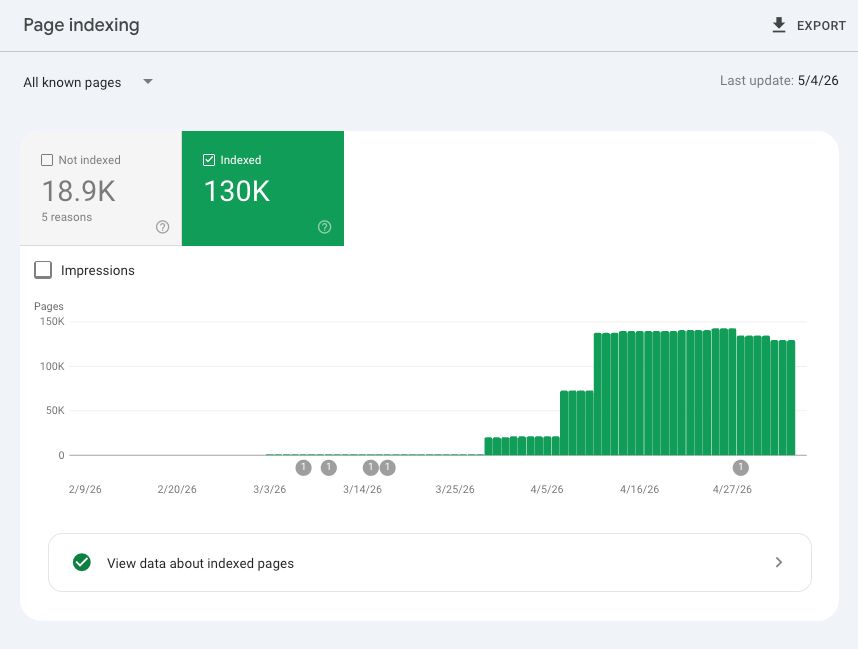
Steep growth curve from 0 → 130K. Largest property by page volume.
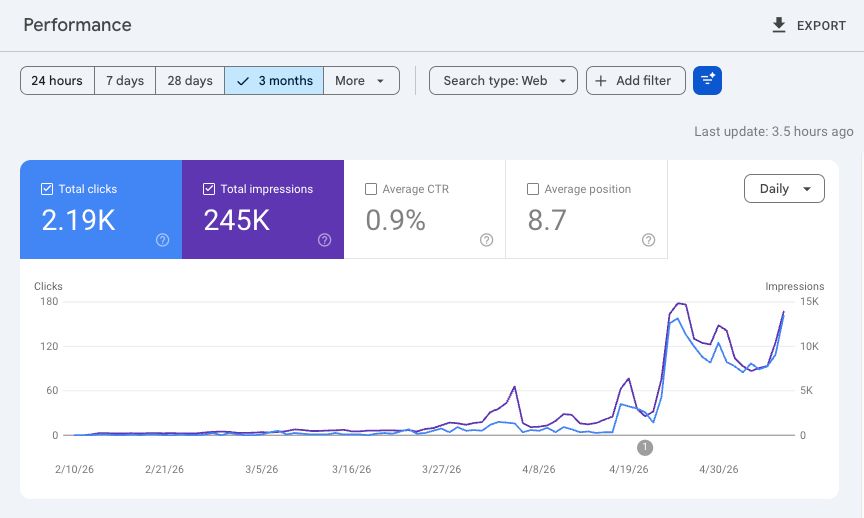
0.9% CTR, avg position 8.7. Highest impression volume.
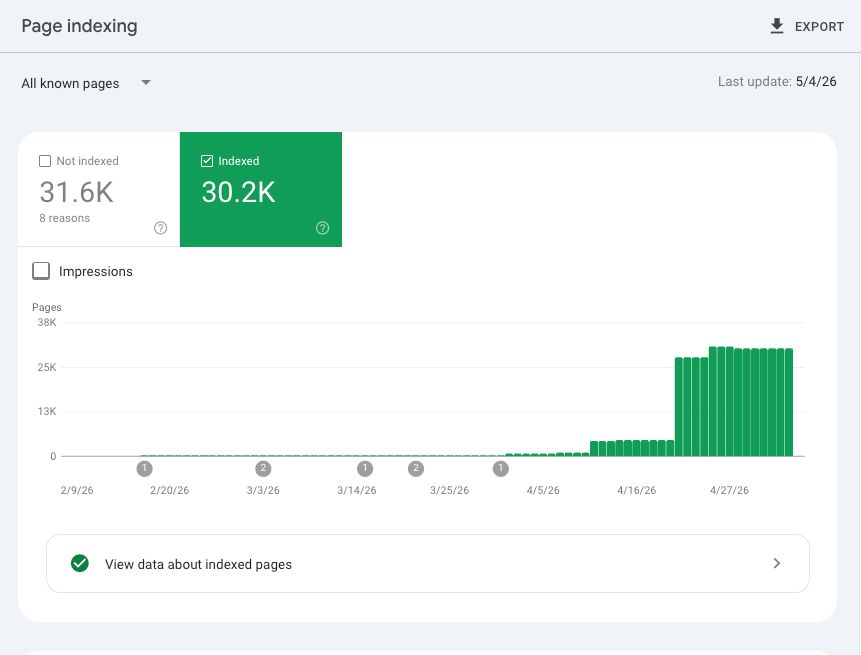
Rapid ramp from 0 → 30.2K. Newest property in pipeline.
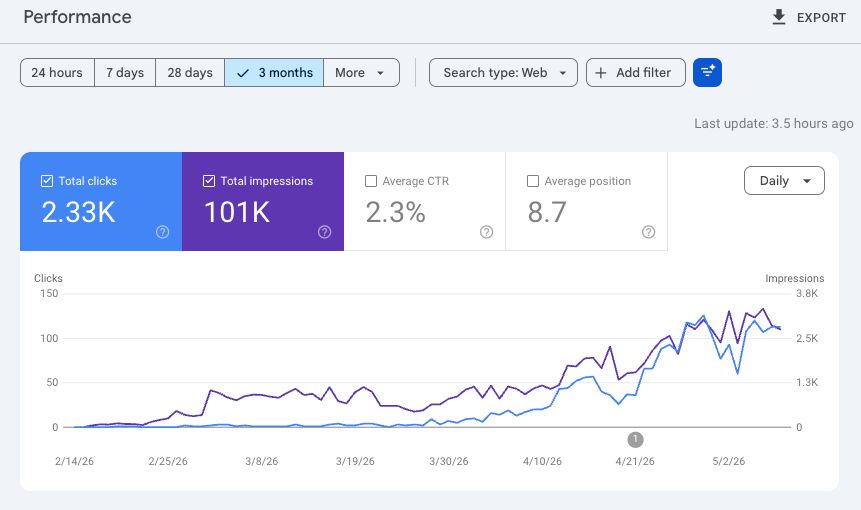
2.3% CTR, avg position 8.7. Highest-converting property.
Live demo
End-to-end pipeline experience — the self-serve interface for autonomous content generation with human-supervised quality gates
Engineering trade-offs
Quality vs. cost
Validation that doesn’t spend a generation budget. Rule-based checks run before the SLM-as-judge layer ever fires — cheap rejections stay cheap. Mechanism documented on the Pipeline page.
Decision: deterministic-first validation, 68.9% pass rate.
Safety vs. throughput
Fail-closed design means ~31% of content is rejected. Intentional — no partial or low-quality content ever propagates downstream to production surfaces.
Decision: fail-closed at every boundary, zero tolerance.
Self-improvement
RLAIF data flywheel. DPO preference pairs generated from Node 6/7 evaluation signals for continuous model alignment.
Decision: closed-loop flywheel, autonomous preference pairs.
Scale vs. locality
5 countries require different linguistic, cultural, and regulatory context. Per-locale context injection increases prompt engineering complexity but eliminates fine-tuning per market.
Decision: context-first architecture, zero-shot locale adaptation.